

项目背景与技术选型
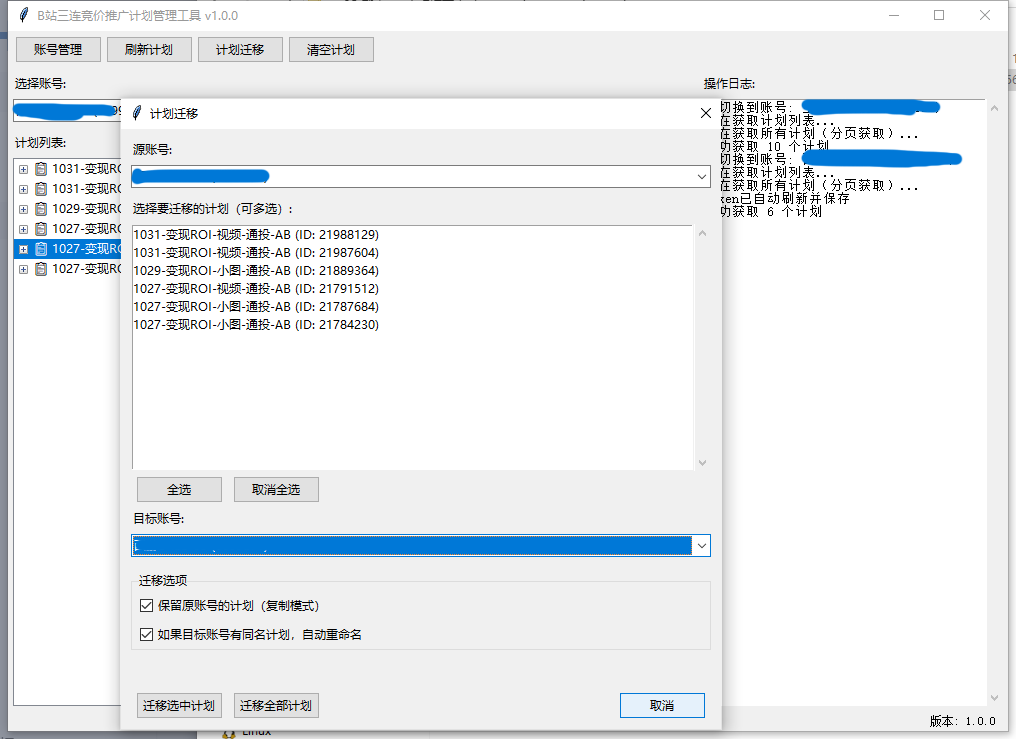
在广告运营工作中,我们面临着一个严峻的技术挑战:如何高效、准确地在不同B站广告账户间迁移广告计划。传统的手动操作方式存在以下技术痛点:
- 数据一致性难保证:手动复制易出错,字段遗漏频繁发生
- API调用频繁:单个广告计划包含计划、单元、创意三层结构,迁移一个计划需要多次API调用
- 创意资源处理复杂:图片、视频等二进制文件的上传和关联逻辑复杂
基于以上痛点,我们选择的技术栈如下:
# 核心技术依赖
requests==2.28.1 # HTTP请求处理
tkinter==8.6 # GUI界面
json==2.0.9 # 数据序列化
logging==0.5.1.2 # 日志管理
threading==3.10 # 异步处理
系统架构设计
核心模块划分
App/
├── core/
│ ├── api_client.py # API客户端封装
│ ├── data_mapper.py # 数据映射处理
│ └── migration_engine.py # 迁移引擎
├── ui/
│ ├── main_window.py # 主窗口
│ ├── account_panel.py # 账号管理面板
│ └── progress_panel.py # 进度显示面板
└── utils/
├── config_manager.py # 配置管理
└── logger.py # 日志工具
数据模型设计
class AdPlan:
def __init__(self):
self.plan_id = None
self.plan_name = ""
self.budget = 0.0
self.schedule = Schedule()
self.units = [] # List[AdUnit]
class AdUnit:
def __init__(self):
self.unit_id = None
self.unit_name = ""
self.bid_strategy = ""
self.creatives = [] # List[Creative]
class Creative:
def __init__(self):
self.creative_id = None
self.title = ""
self.image_url = ""
self.video_url = ""
self.components = [] # List[CreativeComponent]
关键技术实现
1. API客户端封装
class BilibiliAdAPI:
def __init__(self, access_token):
self.base_url = "https://api.bilibili.com/x/ad"
self.access_token = access_token
self.session = requests.Session()
def _make_request(self, endpoint, method='GET', data=None):
"""统一的API请求方法"""
url = f"{self.base_url}/{endpoint}"
headers = {
"Authorization": f"Bearer {self.access_token}",
"Content-Type": "application/json"
}
# 签名生成逻辑
timestamp = str(int(time.time()))
nonce = self._generate_nonce()
signature = self._generate_signature(
method, endpoint, timestamp, nonce, data
)
headers.update({
"X-Timestamp": timestamp,
"X-Nonce": nonce,
"X-Signature": signature
})
try:
response = self.session.request(
method, url, json=data, headers=headers, timeout=30
)
return self._handle_response(response)
except requests.exceptions.RequestException as e:
raise APIRequestError(f"API请求失败: {str(e)}")
def get_plans(self, page=1, page_size=100):
"""获取广告计划列表(支持分页)"""
all_plans = []
current_page = page
while True:
endpoint = f"plans?page={current_page}&page_size={page_size}"
response = self._make_request(endpoint)
plans = response.get('data', {}).get('list', [])
total = response.get('data', {}).get('total', 0)
all_plans.extend(plans)
# 分页逻辑
if len(all_plans) >= total or not plans:
break
current_page += 1
time.sleep(0.1) # 避免API限流
return all_plans
2. 迁移引擎核心实现
class MigrationEngine:
def __init__(self, source_api, target_api):
self.source_api = source_api
self.target_api = target_api
self.mapping_cache = {} # ID映射缓存
def migrate_plan(self, plan_id, callback=None):
"""迁移单个广告计划"""
try:
# 1. 获取源计划数据
source_plan = self.source_api.get_plan_detail(plan_id)
if not source_plan:
raise MigrationError("源计划不存在")
# 2. 数据转换和验证
target_plan_data = self._transform_plan_data(source_plan)
# 3. 创建目标计划
target_plan = self.target_api.create_plan(target_plan_data)
self.mapping_cache['plans'][plan_id] = target_plan['plan_id']
# 4. 迁移关联单元
for unit in source_plan.get('units', []):
self._migrate_unit(unit, target_plan['plan_id'])
if callback:
callback("success", plan_id, target_plan['plan_id'])
return target_plan['plan_id']
except Exception as e:
if callback:
callback("error", plan_id, str(e))
raise
def _migrate_unit(self, source_unit, target_plan_id):
"""迁移广告单元"""
# 处理单元层级的数据转换
unit_data = {
'plan_id': target_plan_id,
'unit_name': source_unit['unit_name'],
'bid_strategy': source_unit['bid_strategy'],
# 其他字段映射...
}
target_unit = self.target_api.create_unit(unit_data)
self.mapping_cache['units'][source_unit['unit_id']] = target_unit['unit_id']
# 迁移创意
for creative in source_unit.get('creatives', []):
self._migrate_creative(creative, target_unit['unit_id'])
def _migrate_creative(self, source_creative, target_unit_id):
"""迁移创意内容"""
# 处理创意资源上传和关联
creative_data = {
'unit_id': target_unit_id,
'title': source_creative['title'],
'components': []
}
# 处理创意组件
for component in source_creative.get('components', []):
if component['type'] == 'IMAGE':
# 下载并重新上传图片
new_image_id = self._reupload_image(component['resource_id'])
creative_data['components'].append({
'type': 'IMAGE',
'resource_id': new_image_id
})
# 处理其他组件类型...
self.target_api.create_creative(creative_data)
3. 并发批量处理
class BatchMigrationManager:
def __init__(self, migration_engine, max_workers=5):
self.engine = migration_engine
self.max_workers = max_workers
self.progress_callbacks = []
def migrate_batch(self, plan_ids):
"""批量迁移计划"""
total = len(plan_ids)
completed = 0
results = {
'success': [],
'failed': []
}
with ThreadPoolExecutor(max_workers=self.max_workers) as executor:
# 提交所有任务
future_to_plan = {
executor.submit(self.engine.migrate_plan, plan_id): plan_id
for plan_id in plan_ids
}
# 处理完成的任务
for future in as_completed(future_to_plan):
plan_id = future_to_plan[future]
try:
target_plan_id = future.result()
results['success'].append({
'source_id': plan_id,
'target_id': target_plan_id
})
except Exception as e:
results['failed'].append({
'plan_id': plan_id,
'error': str(e)
})
completed += 1
self._update_progress(completed, total)
return results
核心技术挑战与解决方案
1. API分页处理优化
def get_all_plans_optimized(self, filters=None):
"""优化版的全量计划获取"""
# 第一次请求获取总数和基础信息
first_page = self.get_plans(page=1, page_size=10)
total_count = first_page['data']['total']
# 根据总数调整分页策略
if total_count <= 100:
page_size = 50
elif total_count <= 1000:
page_size = 100
else:
page_size = 200
# 并行获取后续页面
total_pages = (total_count + page_size - 1) // page_size
pages_to_fetch = range(2, total_pages + 1)
with ThreadPoolExecutor(max_workers=3) as executor:
futures = {
executor.submit(self.get_plans, page, page_size): page
for page in pages_to_fetch
}
all_plans = first_page['data']['list']
for future in as_completed(futures):
page_data = future.result()
all_plans.extend(page_data['data']['list'])
return all_plans
2. 创意资源处理
def _reupload_image(self, source_image_id):
"""重新上传图片资源"""
# 1. 下载源图片
image_data = self.source_api.download_creative_image(source_image_id)
# 2. 上传到目标账户
upload_result = self.target_api.upload_creative_image(
image_data['content'],
image_data['filename'],
image_data['content_type']
)
# 3. 等待审核通过
for _ in range(30): # 最多等待30秒
status = self.target_api.get_creative_status(upload_result['image_id'])
if status == 'approved':
return upload_result['image_id']
elif status == 'rejected':
raise MigrationError(f"图片审核失败: {upload_result['image_id']}")
time.sleep(1)
raise MigrationError("图片审核超时")
3. 错误处理与重试机制
class RetryableOperation:
def __init__(self, max_retries=3, backoff_factor=1.0):
self.max_retries = max_retries
self.backoff_factor = backoff_factor
def execute_with_retry(self, operation, should_retry=None):
"""带重试的执行逻辑"""
last_exception = None
for attempt in range(self.max_retries + 1):
try:
return operation()
except (APIRequestError, ConnectionError) as e:
last_exception = e
if attempt == self.max_retries:
break
if should_retry and not should_retry(e):
break
# 指数退避
sleep_time = self.backoff_factor * (2 ** attempt)
time.sleep(sleep_time)
raise last_exception
性能优化实践
1. 内存优化
class MemoryEfficientMigration:
def stream_migrate_large_account(self, account_id):
"""流式处理大账户迁移,避免内存溢出"""
page_size = 50
page = 1
while True:
# 分批获取计划
plans = self.source_api.get_plans(
account_id, page=page, page_size=page_size
)
if not plans:
break
# 处理当前批次
for plan in plans:
yield self.migrate_plan(plan['plan_id'])
# 及时清理内存
del plans
page += 1
2. 缓存策略
class MigrationCache:
def __init__(self, ttl=3600): # 1小时过期
self.cache = {}
self.ttl = ttl
def get_mapping(self, source_type, source_id):
"""获取ID映射"""
key = f"{source_type}_{source_id}"
if key in self.cache:
data, timestamp = self.cache[key]
if time.time() - timestamp < self.ttl:
return data
else:
del self.cache[key]
return None
def set_mapping(self, source_type, source_id, target_id):
"""设置ID映射"""
key = f"{source_type}_{source_id}"
self.cache[key] = (target_id, time.time())
监控与调试
1. 详细日志记录
def setup_migration_logger():
"""配置迁移日志"""
logger = logging.getLogger('migration')
logger.setLevel(logging.INFO)
# 文件处理器
file_handler = logging.FileHandler('migration.log')
file_formatter = logging.Formatter(
'%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
file_handler.setFormatter(file_formatter)
# 控制台处理器
console_handler = logging.StreamHandler()
console_formatter = logging.Formatter(
'%(levelname)s: %(message)s'
)
console_handler.setFormatter(console_formatter)
logger.addHandler(file_handler)
logger.addHandler(console_handler)
return logger
2. 迁移状态追踪
class MigrationTracker:
def __init__(self):
self.stats = {
'total_plans': 0,
'completed_plans': 0,
'failed_plans': 0,
'start_time': None,
'end_time': None
}
def start_migration(self, total_plans):
"""开始迁移任务"""
self.stats.update({
'total_plans': total_plans,
'start_time': time.time(),
'completed_plans': 0,
'failed_plans': 0
})
def record_success(self, plan_id):
"""记录成功迁移"""
self.stats['completed_plans'] += 1
def record_failure(self, plan_id, error):
"""记录迁移失败"""
self.stats['failed_plans'] += 1
def get_progress(self):
"""获取迁移进度"""
if self.stats['total_plans'] == 0:
return 0.0
return (self.stats['completed_plans'] + self.stats['failed_plans']) / self.stats['total_plans']
总结
通过以上技术方案,我们成功构建了一个稳定高效的B站广告计划迁移工具。该工具在技术实现上主要解决了以下核心问题:
- 大规模数据处理:通过分页、流式处理和并发控制,支持处理上千个广告计划
- 复杂业务逻辑:完整处理计划-单元-创意的三层结构迁移
- 资源依赖管理:自动处理图片、视频等创意资源的重新上传和关联
- 系统稳定性:完善的错误处理、重试机制和状态追踪
- 性能优化:通过缓存、批量操作等技术提升迁移效率
这套技术方案不仅解决了具体的业务需求,也为类似的数据迁移场景提供了可复用的技术框架。
评论区