

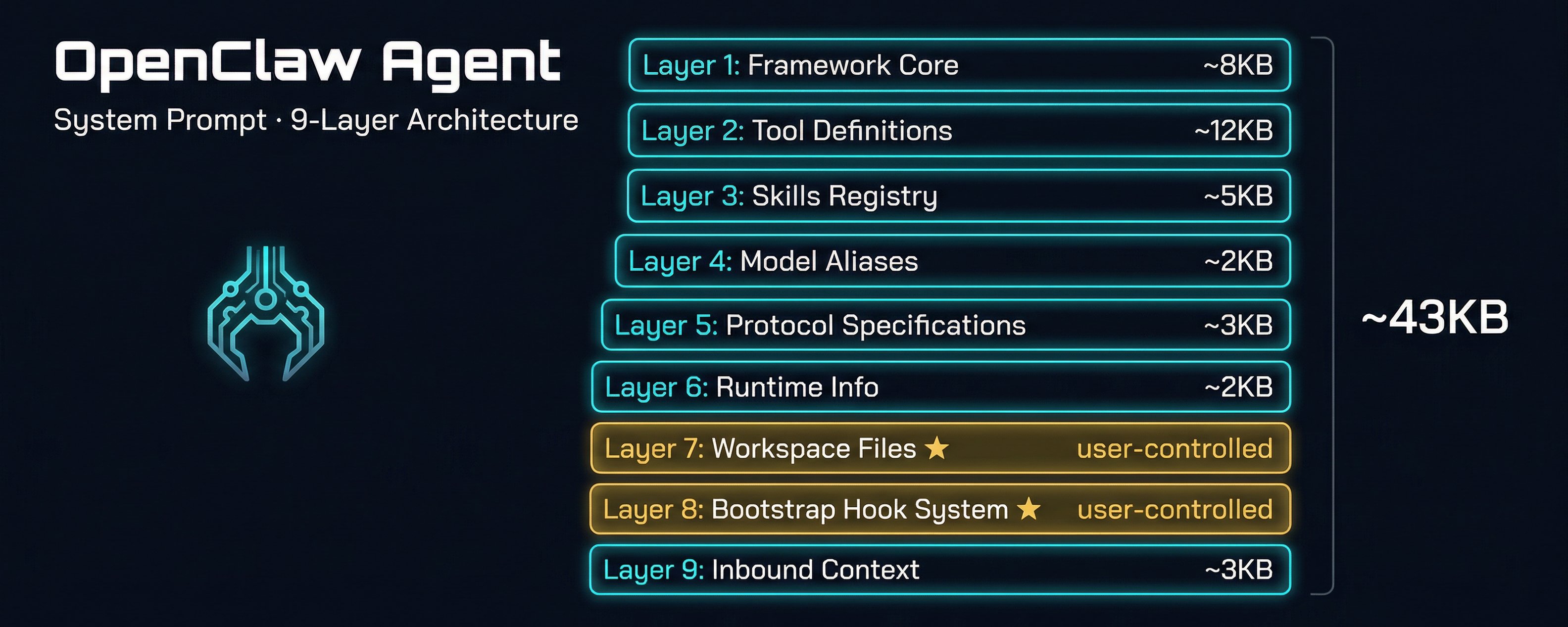
你以为System Prompt就是一堆文字?人家把它做成了9层架构,每一层都有明确的设计权衡。
前两天看到大佬@servasyy_ai发了一篇贴子:《OpenClaw Agent System Prompt架构详解 v2.1》。本来以为是普通的技术文档,结果一看——好家伙,他把一个System Prompt拆成了9层,还画了架构图!
更绝的是,每一层都写了设计权衡:为什么这么设计?有什么好处?代价是什么?看得我直接跪了。
今天我就用大白话,把这“九层妖塔”拆给你看。看懂这个,你就能理解为什么你的token消耗总是控制不住。
看不懂直接丢给你的openclaw看,看完让它照这优化。
🎯 先来个快速导航(给没耐心的人)
新手只需要知道这两层:
- Layer 7(工作区文件):你想改Agent的性格、规则?直接改这里的.md文件
- Layer 8(Bootstrap Hook):你想动态注入实时信息?用这个写脚本
其他层都是框架自动生成的,看看就行,别手贱去改。
常见需求对应:
- 想让Agent有个性?→ 改 Layer 7 的
IDENTITY.md - 想塞项目文档?→ 用 Layer 8 的
bootstrap-extra-files - 想注入当前时间/天气?→ 用
before_prompt_build钩子 - 嫌Prompt太长烧钱?→ 调
bootstrapMaxChars配置
🏛️ 九层妖塔,一层一层拆
Layer 1:框架核心层
就像操作手册的“使用说明”
这层告诉LLM三件事:
- 你是谁(身份设定)
- 你能做什么(能力边界)
- 怎么回应(输出格式)
实际长这样:
你正在以「创意伙伴」身份运行...
当前时间:2026-03-05 14:37:00
=== 工具调用规范 ===
- 使用XML风格的工具调用格式
- 每个工具调用必须包含唯一的tool_call_id
=== 安全边界 ===
- 严禁执行destructive操作
- 敏感信息必须加密存储
💡 设计权衡:灵活vs一致
- 决策:框架统一生成,保证所有Agent基础行为一致
- 好处:用户不用重复配置、框架升级自动获得新能力
- 代价:用户改不了核心规则,特殊需求只能去Layer7/8绕路
Layer 2:工具定义层
就像瑞士军刀的说明书
每个工具都用JSON Schema写得死死的:
{
"name": "read",
"description": "读取文件内容",
"parameters": {
"type": "object",
"properties": {
"path": {"type": "string"},
"offset": {"type": "number"}
},
"required": ["path"]
}
}
💡 设计权衡:灵活vs类型安全
- 决策:用严格的JSON Schema定义工具参数
- 好处:LLM理解更准、调用前可验证参数、自动生成文档
- 代价:加新工具要写完整Schema,没法玩动态参数
Layer 3:技能注册表
就像餐厅的“特色菜谱”
框架自动扫描 ~/skills/ 目录,里面的技能全给Agent学会。
💡 设计权衡:灵活vs维护成本
- 决策:自动扫描目录,不用手动注册
- 好处:加新技能扔文件夹就行,所有Agent自动学会
- 代价:没法精确控制每个Agent用啥技能,所有技能都塞进Prompt(token狂涨的元凶之一!)
Layer 4:模型别名层
就像“快捷键”
给复杂模型起短名字:glm-5 代替 zhipu/glm-5
💡 设计权衡:灵活vs可读性
- 决策:允许为常用模型定义别名
- 好处:调用简单、支持多Provider切换、方便A/B测试
- 代价:要维护别名配置文件,不同Agent可能同名不同模型
Layer 5:协议规范层
就像“交通规则”
定义Agent怎么和系统交互:
- Silent Replies:用户说“收到”,Agent回
NO_REPLY - Heartbeats:系统心跳检查,Agent回
HEARTBEAT_OK
💡 设计权衡:自由vs一致
- 决策:定义标准化交互协议
- 好处:所有Agent行为一致、可自动化监控、多Agent协作不乱
- 代价:限制了Agent的自由发挥,LLM可能不守规矩
Layer 6:运行时信息层
就像“仪表盘”
每次请求都告诉LLM:
- 当前时间
- 当前模型
- 运行环境
- 操作系统
💡 设计权衡:token消耗vs上下文准确
- 决策:每次请求都注入最新运行时状态
- 好处:LLM不会犯“现在是2023年”的低级错误
- 代价:每次请求多花~2KB token
🛠️ Layer 7:工作区文件层(用户可控)
就像“你的工作笔记”
这是你能直接改的静态文件:
IDENTITY.md:定义Agent性格AGENTS.md:写协作规则MEMORY.md:记事儿(建议让MemOS自动管)
💡 设计权衡:框架稳定vs用户自由
- 决策:把“变”和“不变”分离,框架层保证一致,用户层允许个性
- 好处:可定义身份、可版本管理、框架升级不炸配置
- 代价:改不了框架核心行为,得学TELOS框架
🧙 Layer 8:Bootstrap Hook系统(用户可控)
就像“可编程注射器”
四种玩法:
-
agent:bootstrap(最猛)
完全控制文件数组,可以增删改、重排序registerInternalHook("agent:bootstrap", (event) => { context.bootstrapFiles = [{path: "CUSTOM.md", content: "自定义"}] }) -
bootstrap-extra-files(简单)
只追加文件,不改现有的{"paths": ["docs/API.md", "docs/CONTEXT.md"]} -
before_prompt_build(实时)
发消息前修改Prompt,适合注入当前时间on("before_prompt_build", () => { return {prependContext: `当前时间:${new Date()}`} }) -
bootstrapMaxChars(限重)
单文件默认20K,总计150K,超了按头70%+尾20%截断
💡 设计权衡:静态简单vs动态灵活
- 决策:在静态文件之外提供动态Hook机制
- 好处:可根据上下文动态注入、可执行shell命令、支持条件判断
- 代价:要学Hook语法,脚本写崩了Prompt就炸
Layer 9:入站上下文层
就像“实时路况”
每次请求动态注入:
- 谁在说话
- 对话历史
- 是否被@
💡 设计权衡:token消耗vs对话连贯
- 决策:每次请求都注入最新上下文
- 好处:LLM知道谁在说话、记得前文
- 代价:每次~3KB token,历史可能带噪音
📊 用户到底能控哪几层?(重点!)
很多人以为“用户可控”就是改配置文件,其实OpenClaw给了3种控制方式:
| 控制方式 | 代表层 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|---|
| 静态配置 | Layer 7 | 定义身份、规则、记忆 | 简单直观,可版本管理 | 没法动态调整 |
| 动态脚本 | Layer 8 | 根据上下文实时注入 | 灵活强大,支持条件判断 | 要学Hook,脚本崩了就炸 |
| 间接影响 | Layer 9 | 通过发消息引导LLM | 自然交互,不用配置 | 没法精确控制 |
真正能省token的,就是Layer 7和Layer 8!
💡 优化建议(亲测有效)
Layer 7优化:
- ✅
IDENTITY.md用表格代替长篇大论 - ✅
MEMORY.md让MemOS自动管,别手写 - ❌ 别重复描述框架已经知道的事
- ❌ 别把Skills说明复制进来
Layer 8优化:
- ✅ 简单场景用
bootstrap-extra-files - ✅ 需要条件判断用
agent:bootstrap - ✅ 需要实时上下文用
before_prompt_build - ❌ 别在Hook里干耗时操作
- ❌ 别用不稳定的外部依赖
超长文件处理:
- 默认截断策略:头70% + 尾20%,中间不要了
- 为啥?因为文档中间通常最水
🎬 最后说两句
看完这篇拆解,我才明白:OpenClaw的System Prompt不是一坨文字,而是一个精心设计的软件架构。
- Layer 1-6:框架自动搭,稳如老狗
- Layer 7-8:用户来装修,个性拉满
- Layer 9:实时情报,保持在线
每一层都有明确的设计权衡——知道为什么这么设计,比知道怎么配置更重要。
原文里有完整的架构图和代码示例,想看原汁原味的技术文档,可以找@servasyy_ai的置顶帖。
最后手动艾特大佬:这九层妖塔的拆解,属实是喂到嘴边的龙虾了!
评论区